- Description:
- Demonstrates a gated recurrent unit (GRU) example with the use of fully-connected, Tanh/Sigmoid activation functions.
- Model definition:
- GRU is a type of recurrent neural network (RNN). It contains two sigmoid gates and one hidden state.
- The computation can be summarized as:
z[t] = sigmoid( W_z ⋅ {h[t-1],x[t]} )
r[t] = sigmoid( W_r ⋅ {h[t-1],x[t]} )
n[t] = tanh( W_n ⋅ [r[t] × {h[t-1], x[t]} )
h[t] = (1 - z[t]) × h[t-1] + z[t] × n[t]
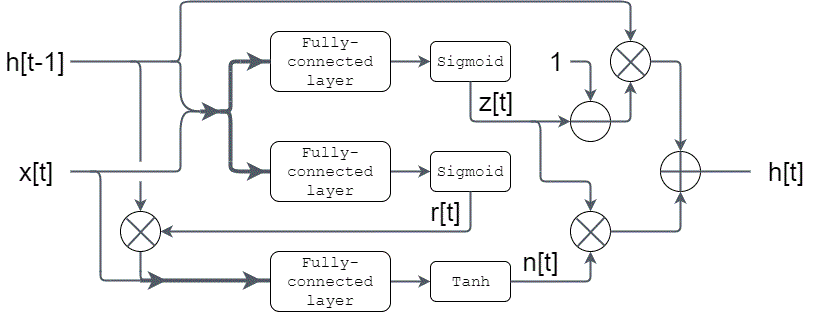
Gate Recurrent Unit Diagram
- Variables Description:
update_gate_weights, reset_gate_weights, hidden_state_weights are weights corresponding to update gate (W_z), reset gate (W_r), and hidden state (W_n). update_gate_bias, reset_gate_bias, hidden_state_bias are layer bias arrays test_input1, test_input2, test_history are the inputs and initial history
- The buffer is allocated as:
- | reset | input | history | update | hidden_state |
- In this way, the concatination is automatically done since (reset, input) and (input, history) are physically concatinated in memory.
- The ordering of the weight matrix should be adjusted accordingly.
- NMSIS NN Software Library Functions Used:
-
Refer riscv_nnexamples_gru.c